PlaIR 2.018 (2015-2020) est un projet interdisciplinaire réunissant le laboratoire LITIS (Laboratoire d’Informatique Traitement de l’Information et des Systèmes) et l’IRIHS (Institut de Recherche Interdisciplinaire Homme Société) autour de la question de l’indexation documentaire. PlaIR 2.018 étend les objectifs des projets PlaIR (2009-2012) et PlaIR 2.0 (2013-2016), en s’ouvrant aux humanités numériques, notamment dans le domaine du patrimoine numérique et du droit.
PlaIR 2.018 couvre l’ensemble de la chaîne éditoriale numérique pour Numériser, Transformer, Enrichir, Éditer et Exposer des ressources documentaires. Le projet se décline en 4 actions en interaction :
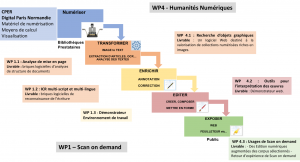
WP1 : Scan On Demand : Développement de technologies de Machine Learning pour instancier des chaînes de numérisation et des moteurs d’indexation de corpus écrits du patrimoine Normand.
WP4 : Humanités Numériques : Constitution de corpus et développement de technologies du web pour l’édition critique numérique des grands corpus écrits du patrimoine Normand.
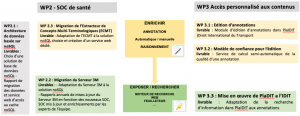
WP2 : SOC de santé : Développement de Systèmes d’Organisation de Connaissances et de Big Data dans le domaine de la santé.
WP3 : Accès personnalisé aux contenus : Développement de technologies d’Intelligence Artificielle pour l’aide à l’interprétation des textes réglementaires dans le domaine du droit international des transports.